อัลกอริทึมที่ประมาณค่าได้แปรผันกับข้อมูลนำเข้า
ปัญหาทางการคำนวณหลายปัญหามีความยากขั้น NP ซึ่งหมายความว่าเราไม่สามารถหาอัลกอริทึมที่เร็วพอเพื่อแก้ปัญหาเหล่านั้นได้ ทางออกหนึ่งก็คือเลิกคิดถึงอัลกอริทึมเพื่อหาคำตอบที่ดีที่สุด แล้วเปลี่ยนไปคิดอัลกอริทึมที่ไม่ช้าจนเกินไปแม้จะได้คำตอบเป็นค่าประมาณก็ตาม
ถ้าเราพิสูจน์ได้ว่าอัลกอริทึมแบบประมาณนั้น ให้ที่คำตอบไม่แย่ไปกว่า 2 เท่าของคำตอบที่ดีที่สุด (สำหรับทุกๆ ความเป็นไปได้ของข้อมูลนำเข้า) อัลกอริทึมดังกล่าวจะเป็นแบบ 2-approximation สังเกตว่าเลข 2 นี่เป็นค่าคงที่และไม่ขึ้นกับขนาดของข้อมูลนำเข้า
แต่ก็ยังมีอัลกอริทึมประมาณอีกประเภท ที่ไม่สามารถประมาณคำตอบเป็นค่าคงที่ของคำตอบที่ดีที่สุด บทความนี้จะใช้ปัญหาการปกคลุมเซตเป็นตัวอย่าง
ปัญหาการปกคลุมเซต (set cover problem) ให้ข้อมูลนำเข้าเป็นเซต $S$ ซึ่งมีสมาชิกจำนวน $m$ ตัว โดยสมาชิกแต่ละตัวเป็นเซต (เรียกเซตเหล่านั้นว่า $s_1$, $s_2$, ไปจนถึง $s_m$) และเรียกยูเนียนของ $S$ ว่ายูนิเวอร์ส $U = \bigcup S$ (และเพื่อความสะดวก ให้ $n = \abs{U}$) คำถามคือให้หา $S^\ast$ ซึ่งเป็นซับเซตของ $S$ โดยที่ $S^\ast$ มีขนาดเล็กที่สุดที่ยูเนียนของมันยังได้ผลลัพธ์เป็นยูนิเวอร์ส $U = \bigcup S^\ast$ อยู่
ตัวอย่างเช่น $S = \lbrace \lbrace1,2,3\rbrace, \lbrace1,4\rbrace, \lbrace2,5\rbrace, \lbrace3,6\rbrace, \lbrace1\rbrace, \lbrace2\rbrace, \lbrace3\rbrace \rbrace$ จะเห็นว่า $U = \lbrace1,2,3,4,5,6\rbrace$ และคำตอบ (ที่ดีที่สุด) ของปัญหานี้คือ $S^\ast = \lbrace \lbrace1,4\rbrace, \lbrace2,5\rbrace, \lbrace3,6\rbrace \rbrace$ ซึ่งมีขนาดคำตอบเท่ากับ 3 เซต
แผนภาพออยเลอร์ของเซตตัวอย่างข้างต้น
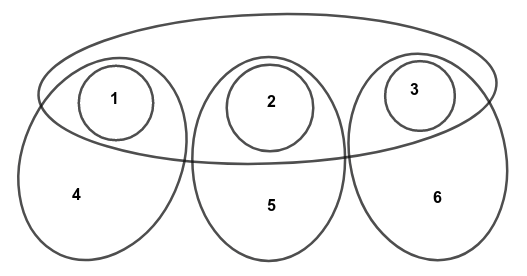
อัลกอริทึมประมาณค่าที่ทำงานแบบละโมบ จะเลือกหยิบ $s_x \in S$ ที่ลดจำนวนสมาชิกใน $U$ ได้มากที่สุดมาใส่ในคำตอบ $S^\ast$ แล้วคำนวณ $U’ = U \setminus s_x$ และ $S’ = \lbrace s \in S : s \neq s_x \rbrace $ ถึงตอนนี้ถ้ายูนิเวอร์ส $U’$ ยังไม่เป็นเซตว่าง ก็จะวนกลับไปทำงานตามข้างต้นซ้ำเรื่อยๆ (โดยให้ $U \gets U’$ และ $S \gets S’$) จนกว่ายูนิเวอร์สจะกลายเป็นเซตว่างนั่นเอง
จากตัวอย่างข้างต้นแต่เปลี่ยนมาใช้อัลกอริทึมแบบละโมบ จะได้ว่ารอบแรกเราเลือกหยิบ $\lbrace1,2,3\rbrace$ เพราะเซตนี้ลดขนาดของยูนิเวอร์สได้มากที่สุด แล้วอีก 3 รอบต่อมาเราจะหยิบ $\lbrace1,4\rbrace, \lbrace2,5\rbrace, \lbrace3,6\rbrace$ (ในลำดับใดก็ได้) ถึงตอนนี้เราก็จะได้คำตอบแบบประมาณของคำถามนี้เรียบร้อย โดยขนาดของคำตอบแบบประมาณนี้คือ 4 เซต ดังนั้นสัดส่วนการประมาณจึงเป็น 4/3 เท่าของคำตอบที่ดีที่สุด
แล้วคำตอบแบบประมาณที่ได้จากอัลกอริทึมนี้ต่อข้อมูลนำเข้าใดๆ มีสัดส่วนเป็นเท่าไหร่หละ? หากลองสร้างตัวอย่างอื่นมาดูเรื่อยๆ จะพบว่าค่าประมาณนั้นไม่ได้เป็นจำนวนเท่าแบบค่าคงที่เลย
วิธีหาสัดส่วนค่าประมาณของอัลกอริทึมนี้ เริ่มด้วยการสมมติก่อนว่าคำตอบที่ดีที่สุดมีขนาดเป็น $k$ เซต เนื่องจากอัลกอริทึมเป็นแบบละโมบ ดังนั้นรอบแรกของอัลกอริทึม เซต $s_x$ ที่ถูกเลือกจะต้องมีขนาดอย่างน้อย $n(\frac1k)$ ทำให้ยูนิเวอร์ส $U’$ มีขนาดเหลือได้อย่างมาก $n(1-\frac1k)$
ในรอบที่สอง เซตที่ถูกเลือกจะมีขนาดอย่างน้อย $n(1-\frac1k)(\frac1k)$ และจะทำให้ยูนิเวอร์สมีขนาดลดลงเหลืออย่างมาก $n(1-\frac1k) - n(1-\frac1k)(\frac1k) = n(1-\frac1k)^2$
หลังจากอัลกอริทึมทำงานไป $i$ รอบ ขนาดของยูนิเวอร์สจะเหลืออย่างมาก $n(1-\frac1k)^i$ สนใจรอบที่ $i = k \ln n$ จะเห็นว่ายูนิเวอร์สมีขนาดเหลืออย่างมากแค่ $n(1-\frac1k)^{k \ln n} < n(\frac1e)^{\ln n} = 1$
นั่นหมายความว่าอัลกอริทึมแบบละโมบจะทำงานอย่างมากสุดแค่ $k \ln n$ รอบ และเพราะแต่ละรอบ $S^\ast$ จะมีสามชิกเพิ่มขึ้นหนึ่งตัว ดังนั้นเซตคำตอบจะมีขนาดใหญ่สุดเป็น $k \ln n$ หรือเรียกได้ว่าอัลกอริทึมนี้เป็นแบบ $O(\log n)$-approximation นั่นเอง

author